kmem accounting导致的cgroup泄漏问题
现象描述
宿主机上创建容器时失败,kubelet log中可见报错信息mkdir /sys/fs/cgroup/memory/kubepods/burstable/pod79fe803c-072f-11e9-90ca-525400090c71/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b: no space left on devic
这个问题是kubernetes 1.9版本引入的,kubelet创建容器时EnableKernelMemoryAccounting导致的。kernel memory 在内核4.0以下的版本只是一个实验特性,存在使用后不能删除cgroup的问题,造成cgroup泄漏。
Kernel memory support is a work in progress, and the current version provides basically functionality. (See Section 2.7)
关于这个问题的复现和分析,网络上有很多文章, 解决方案简单总结就是宿主机重启+关闭kmem accounting的kubelet。
- k8s社区issue https://github.com/kubernetes/kubernetes/issues/61937
- moby 社区的issue https://github.com/moby/moby/issues/29638
- 腾讯的分析https://tencentcloudcontainerteam.github.io/2018/12/29/cgroup-leaking/
- 还有这篇http://www.linuxfly.org/kubernetes-19-conflict-with-centos7/?from=groupmessage
kakuli同学这篇文章cgroup泄露问题对kubelet相关代码进行了详细的分析,并提供了1.12.4版本(我们的线上版本)的修复方案。 k8s社区在版本1.14,提供了开关可以关闭kmem accounting。
1.cgroup泄漏到底在泄漏什么
内核对于每个cgroup子系统的的条目数是有限制的,限制的大小定义在kernel/cgroup.c #L139 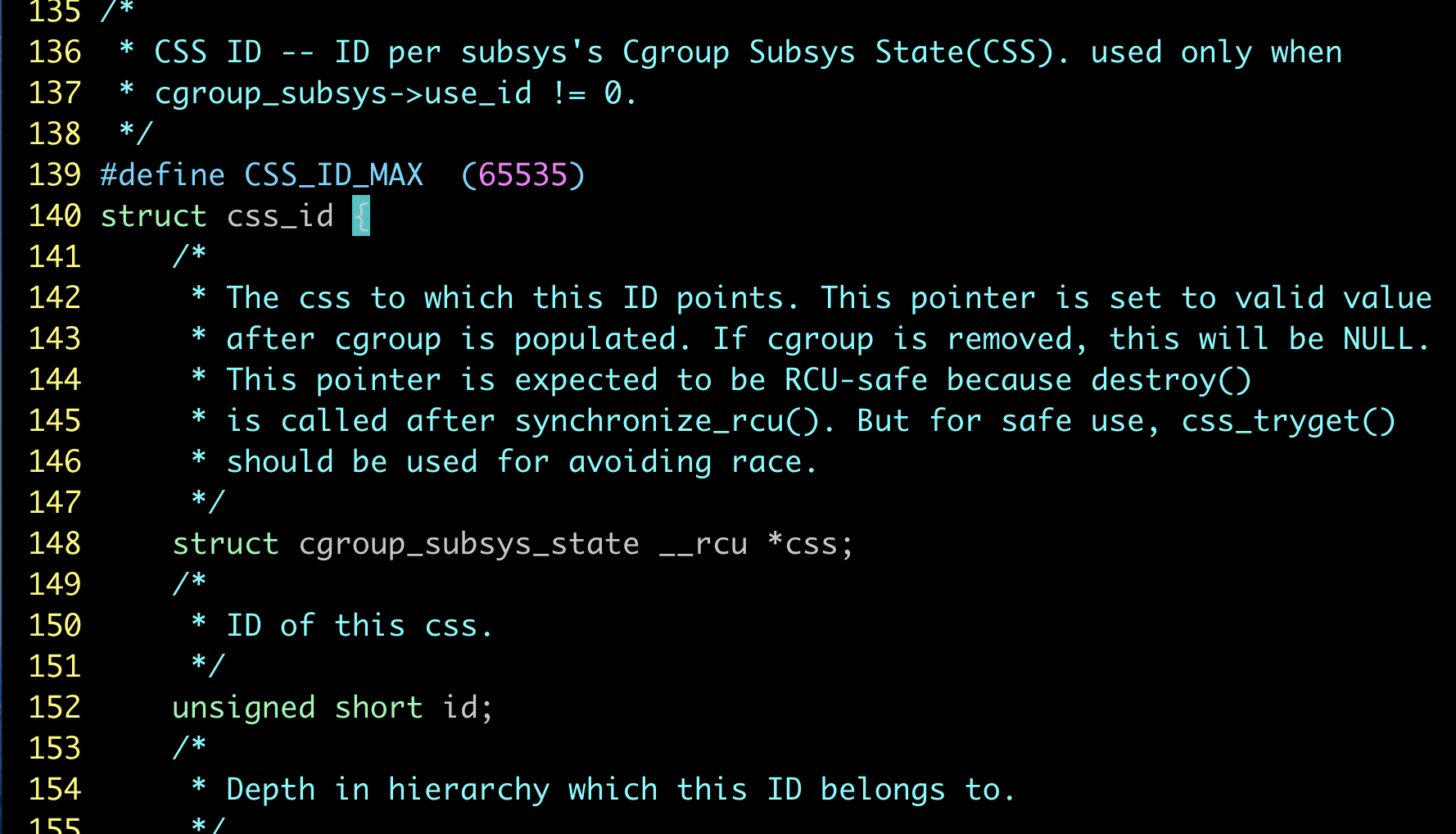 。
。
当正常在cgroup创建一个group的目录时,条目数就加1 .我们遇到的情况就是因为开启了kmem accounting功能,虽然cgroup的目录删除了,但是条目没有回收。这样后面就无法创建65535个cgroup了。也就是说,在当前内核版本下,开启了kmem accounting功能,会导致memory cgroup的条目泄漏无法回收。
2.如何判断是否存在cgroup泄漏
网上提供的方式一般是通过 cat /sys/fs/cgroup/memory/kubepods/memory.kmem.slabinfo。 如果输出如下,则不存在泄漏,
cat: /sys/fs/cgroup/memory/kubepods/memory.kmem.slabinfo: Input/output error
如果输出如下,则说明存在泄漏
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
3.能否精确判断cgroup泄漏程度
经过跟内核组亚方同学请教,可以通过如下方式获取cgroup的num
...
int get_memcg_count(void)
{
struct cgroup_subsys_state *tmp;
int count = 1;
int i;
rcu_read_lock();
for (i = 1; i < 65536; i++) {
tmp = css_lookup(&mem_cgroup_subsys, i);
if (tmp)
count++;
}
rcu_read_unlock();
return count;
}
...
这个统计是包含已释放的和未释放的cgroup条目数,然后和cat /proc/cgroups |awk '{if($1~"memory") print $3}'获取到的memory num_cgroups相减就是泄漏的cgroup数目。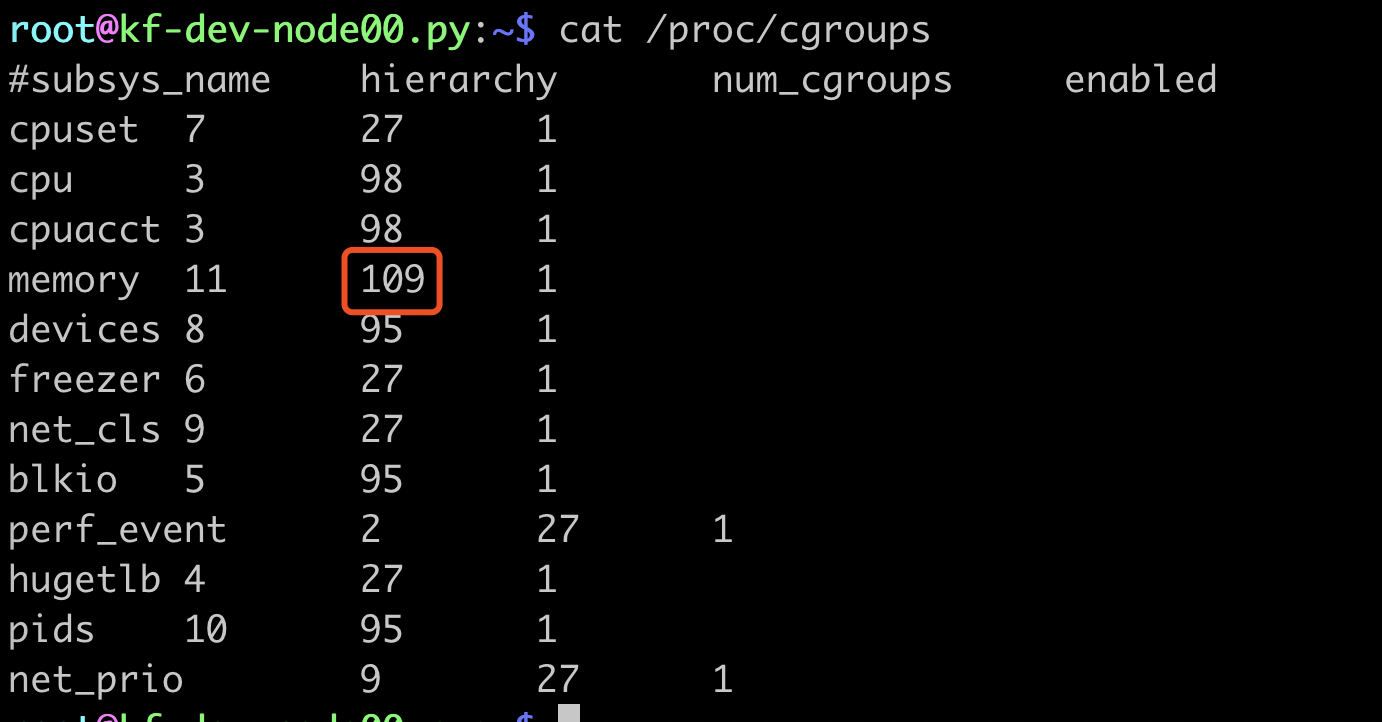 不过对于我们来说,这个stap脚本已经够用了,我们只需要知道还剩多少条目,是否能够完成修复就行了。
不过对于我们来说,这个stap脚本已经够用了,我们只需要知道还剩多少条目,是否能够完成修复就行了。
4.cgroup迁移
对于已经泄漏的memcg(memory cgroup简称),新创建的容器会继承父group,所以会加剧泄漏。如果我们通过一种cgroup迁移方式,将当前的memcg 迁移到另一个group,然后重新创建关闭了kmem accounting的group,并把原来的子group迁移回来, 是否就可以搞定这个问题了呢? 答案是肯定的,这里要感谢我们组最先提出和做cgroup迁移尝试的谭霖同学。
cgroup 本身是支持迁移功能的。
4.2 Task migration
When a task migrates from one cgroup to another, its charge is not
carried forward by default. The pages allocated from the original cgroup still
remain charged to it, the charge is dropped when the page is freed or
reclaimed.
You can move charges of a task along with task migration.
See 8. "Move charges at task migration"
...
This feature is disabled by default. It can be enabledi (and disabled again) by
writing to memory.move_charge_at_immigrate of the destination cgroup.
If you want to enable it:
# echo (some positive value) > memory.move_charge_at_immigrate
Note: Each bits of move_charge_at_immigrate has its own meaning about what type
of charges should be moved. See 8.2 for details.
Note: Charges are moved only when you move mm->owner, in other words,
a leader of a thread group.
Note: If we cannot find enough space for the task in the destination cgroup, we
try to make space by reclaiming memory. Task migration may fail if we
cannot make enough space.
Note: It can take several seconds if you move charges much.
全量task 迁移,因此也不存在上面注意事项中提到的只支持迁移主线程的问题。
那我们梳理下,memcg 需要迁移需达到哪些目标。
- 容器内存quota不变
- 容器的内存使用量不变
- 容器内的进程(对于cgroup来说,都是task)迁移后不丢
这三项分别对应的
- memory.limit_in_bytes
- memory.usage_in_bytes
- tasks
不像memory.limit_in_bytes那样, memory.usage_in_bytes是只读的,因为内存使用量是memcg自身统计的。usage的数据迁移依赖于task迁移来完成。
4.迁移测试
基于前面的分析,梳理出的迁移步骤大致如下
-
检查cgroup剩余条目数
65535-stap获取的已使用条目数是否支持迁移,大于 cat /proc/cgroups |awk '{if($1~"memory") print $3}',否则只能重启宿主解决
停止kubelet,替换kubelet为关闭kmem accounting功能的版本
打开task migration 开关(虽然kernel doc上说打开目标的task migration即可,我们都打开)
创建新的group /sys/fs/cgroup/memory/kubepods2
将/sys/fs/cgroup/memory/kubepods下的子group对应的memory.limit_in_bytes和tasks迁移到新的/sys/fs/cgroup/memory/kubepods2
迁移过程中逐步删除各个子group,直到/sys/fs/cgroup/memory/kubepods被删除
重新创建/sys/fs/cgroup/memory/kubepods, 将/sys/fs/cgroup/memory/kubepods2的子group迁移回/sys/fs/cgroup/memory/kubepods
启动kubelet
重启cadvisor
迁移前的slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
迁移后的slabinfo
cat: /sys/fs/cgroup/memory/kubepods/memory.kmem.slabinfo: Input/output error
在kubepods目录下创建删除目录,检查是否可以被回收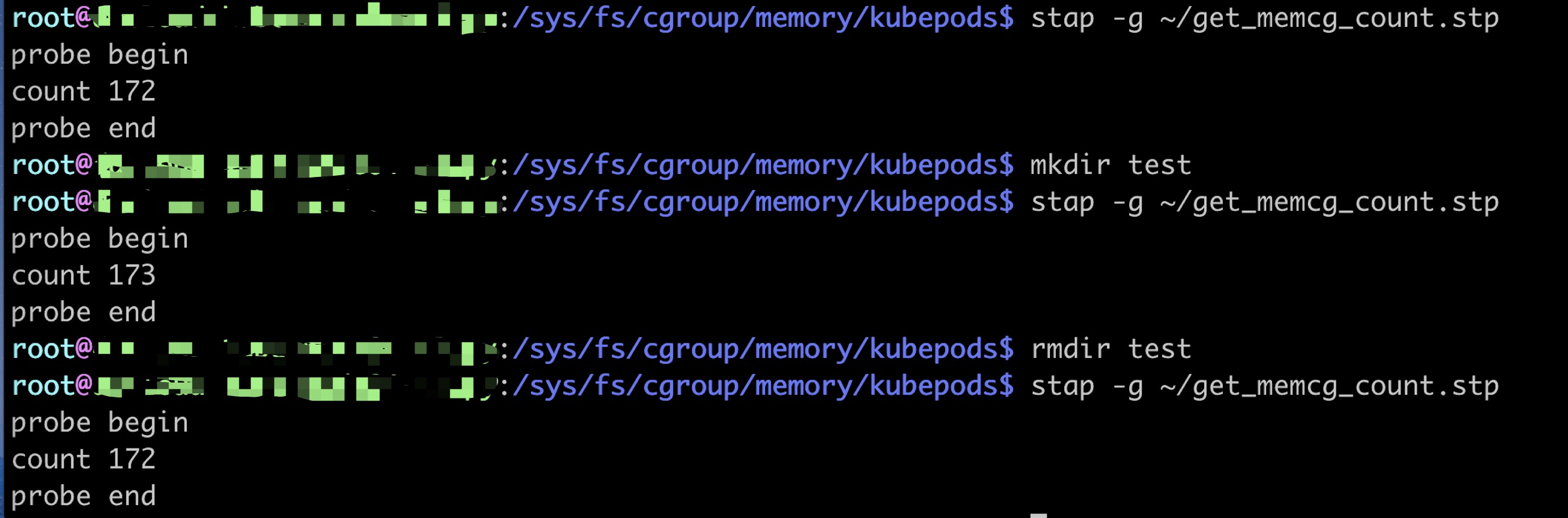 监控出现预期内的断点(cadvisor读取不到数据),内存使用量和使用率下降(task migration 不支持page cache迁移,这也是我们主动drop cache的原因, cache数据会在迁移后随着task使用增加)
监控出现预期内的断点(cadvisor读取不到数据),内存使用量和使用率下降(task migration 不支持page cache迁移,这也是我们主动drop cache的原因, cache数据会在迁移后随着task使用增加)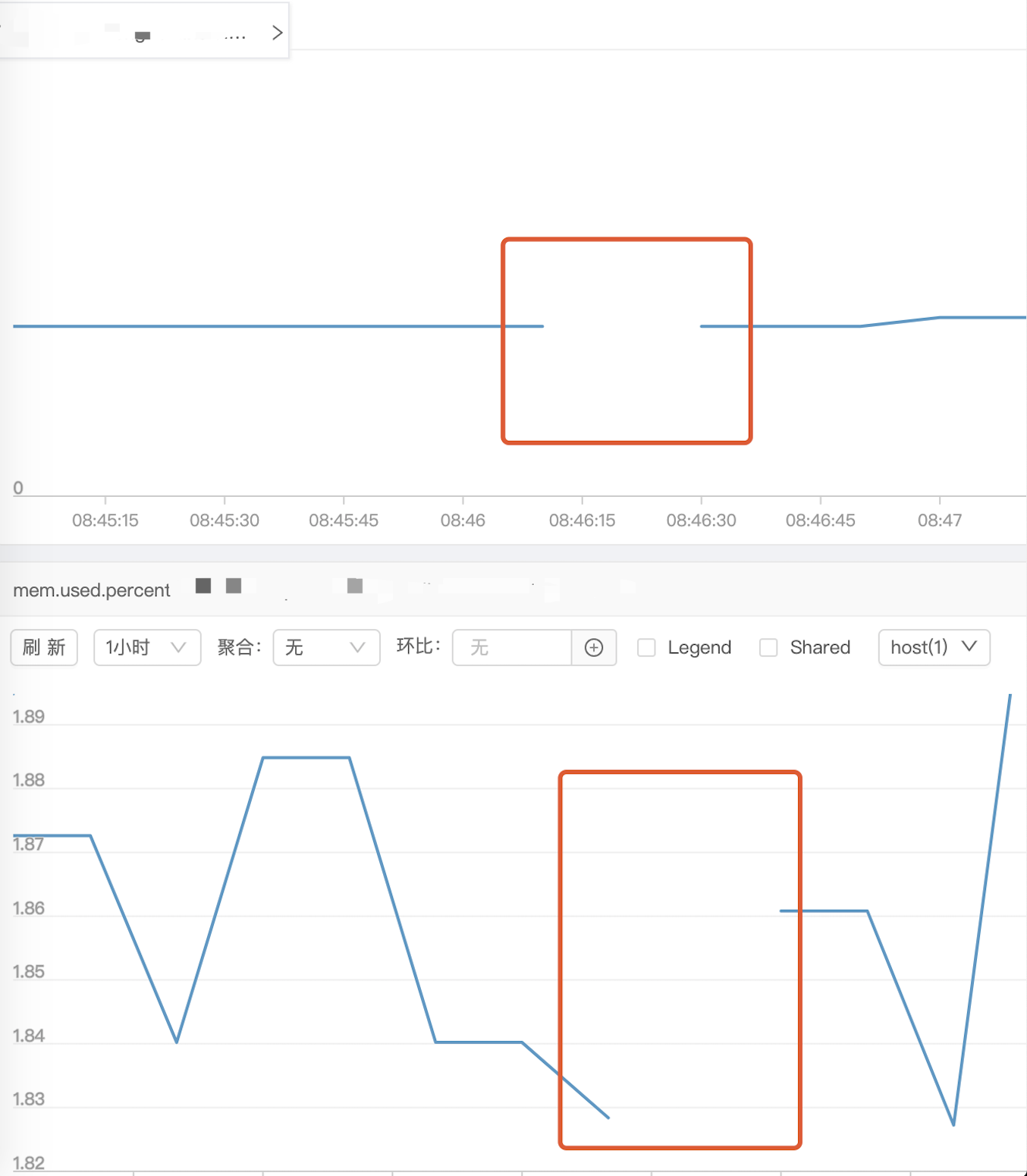
5.主要实现
线上容器的memcg存在两种组织格式,第二种比第一种少了besteffort/bustable层级,所以按照单一目录层级的修复方式不可行。
/sys/fs/cgroup/memory/kubepods/{besterffort,bustable}/podxxxx/xxxx
/sys/fs/cgroup/memory/kubepods/podxxxx/containerxxx
因为需要先从子孙cgroup向父级cgroup逐级迁移和删除,所以kubepods的遍历也需要从叶子向根处理。 这里先将kubepods转换成一个LCRS树,接下来按照中序遍历即可。
func buildTree(path string) (*Node, error) {
stack := NewStack()
root := &Node{
value: path,
sibling: nil,
}
stack.Push(root)
for !stack.IsEmpty() {
cur := stack.Pop().(*Node)
dirs, _, err := walk(cur.value.(string))
if err != nil {
return nil, err
}
for i, dir := range dirs {
c := &Node{
value: dir,
}
if i == 0 {
cur.child = c
cur = c
} else {
cur.sibling = c
cur = cur.sibling
}
stack.Push(c)
}
}
return root, nil
}
中序遍历的过程中做目标目录的创建和迁移
func inorderTraverse(root *Node, src, dst string) {
if root == nil {
return
}
s := NewStack()
n := root
for n != nil || !s.IsEmpty() {
if n != nil {
s.Push(n)
n = n.child
} else {
e := s.Pop().(*Node)
n = e.sibling
dir := e.value.(string)
// 创建目标目录
dstDir := strings.Replace(dir, src, dst, -1)
if _, err := os.Stat(dstDir); os.IsNotExist(err) {
fmt.Printf("mkdir %s \n", dstDir)
err = os.MkdirAll(dstDir, 0755)
if err != nil {
log.Printf("mkdir %s error %s\n", dstDir, err)
continue
}
}
// 打开迁移开关
cmd := fmt.Sprintf("echo 1 > %s", dstDir + "/memory.move_charge_at_immigrate")
output, err:= execCommand(cmd)
if err !=nil {
log.Printf("%s error %s with output\n", cmd , err, output)
continue
}
dirs, files, err := walk(dir)
if err != nil {
log.Println(err)
continue
}
for _, file := range files {
// 迁移容器的内存 quota
// 迁移task cgroup.procs 和tasks 操作一个即可
if strings.HasSuffix(file, "memory.limit_in_bytes") ||
strings.HasSuffix(file, "cgroup.procs") {
dstFile := strings.Replace(file, src, dst, -1)
for retry := 0; retry < 3; retry++ {
err = copyConf(file, dstFile)
if err == nil {
break
}
log.Println(err)
}
}
}
if len(dirs) == 0 {
// drop page cache 不丢弃会记录父group中
cmd := fmt.Sprintf("echo 0 > %s/memory.force_empty", dir)
output, err := execCommandWithRetry(cmd, 3, 100)
if err !=nil {
log.Printf("drop cache cmd: %s err:%s with output:%s\n", cmd, err, output)
}
// 清理迁移完成的cgroup
fmt.Printf("rmdir %s\n", dir)
cmd = fmt.Sprintf("rmdir %s", dir)
output, err = execCommandWithRetry(cmd, 3, 100)
if err != nil {
log.Printf("rmdir %s err:%s with output:%s\n", dir, err, output)
}
}
}
}
}
完整实现见 https://github.com/kongfei605/cgroup_leak_fix
版权所有,转载请注明作者和出处
6.参考资料
[1]. https://www.malasuk.com/doc/kernel-doc-3.10.0/Documentation/cgroups/memory.txt
[2]. https://github.com/kubernetes/kubernetes/issues/61937
[3]. https://github.com/moby/moby/issues/29638
[4]. https://tencentcloudcontainerteam.github.io/2018/12/29/cgroup-leaking/
[5]. http://www.linuxfly.org/kubernetes-19-conflict-with-centos7/?from=groupmessage
[6]. http://likakuli.com/post/2019/06/cgroup%E6%B3%84%E9%9C%B2/