kubernetes监控
kubernetes监控
云原生包含了开源软件、云计算和应用架构的元素。云计算解决开源软件的运行门槛问题,同时降低了运维成本和基础架构成本; 云原生给出了更多的应用架构规范, 更聚焦于能力和生态。随着kubernetes在基础设施的大规模落地,监控的需求也发生了变化,建设一套更符合云原生规范的监控体系势在必行。
一 监控需求变化
- 指标周期变短: 相比物理机时代, 基础设施动态化,Pod销毁重建非常频繁,监控指标跟随Pod的生命周期。
- 指标数量增加: 随着微服务化流行,指标的数量也大幅增长,研发工程师也更愿意埋点,获取服务状态;各种采集器层出不穷,指标应采尽采
- 指标维度更加丰富:物理机时代监控多从资源视角出发,更关注机器、交换机、中间件的采集;新的监控维度更加丰富,维度标签动辄几十上百个,甚至组合会有高基数问题
- 基础设施复杂度变高,监控难度增加:kubernetes组件和应用架构模型都需要投入时间去了解学习。kubernetes本身组件都通过/metrics接口暴露了监控数据,但是缺少体系化的文档指导和最佳实践总结
- 自动发现更重要:相比物理机时代的静态采集,自动发现采集目标的能力变得更重要
监控的一般套路就是确定采集目标,确定采集方式,指标可视化+报警规则。
二 采集目标
2.1 从kubernetes架构看采集目标
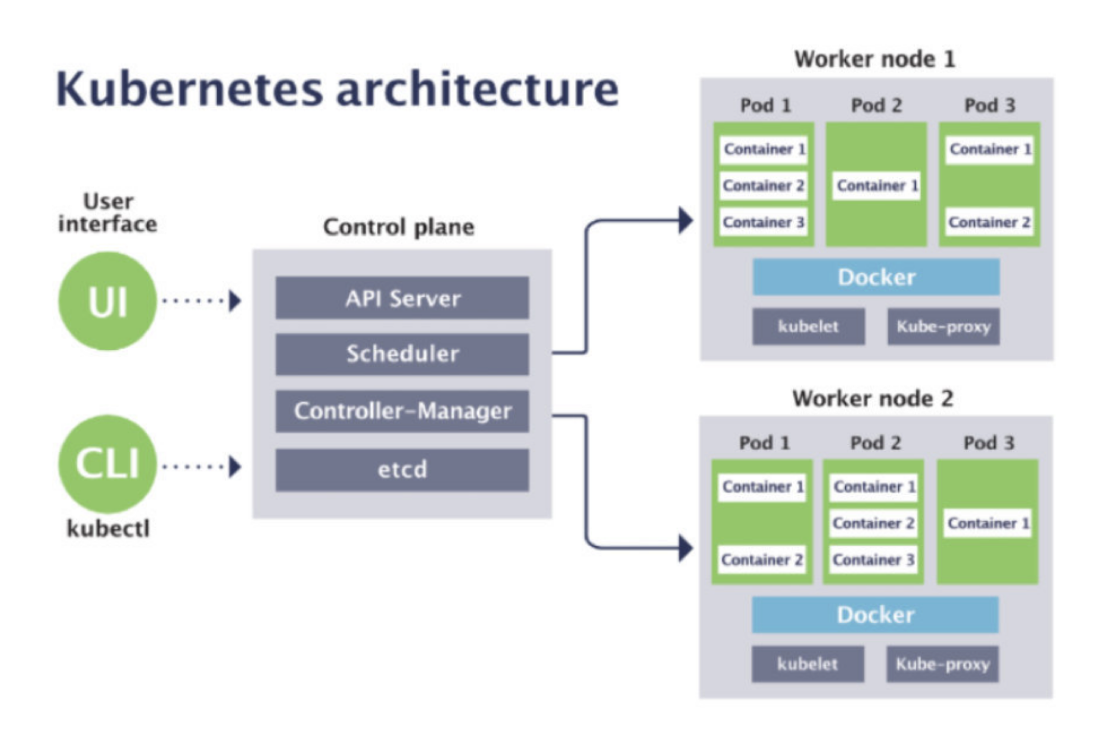
- 控制面组件监控 包括kube-apiserver/kube-controller-manager/kube-scheduler/etcd的监控;
- node组件监控 包括 kubelet/kube-proxy等组件的监控;
- 工作负载及资源监控、 物理集群资源监控
- 业务自身监控 业务自身的状态监控
2.2 简单梳理监控指标
2.2.1 kube-apiserver
kube-apiserver是kubernetes的总入口,其他kubernetes组件的功能都是通过与kube-apiserver交互实现各种功能 + 要处理各种api调用,需要重点关注吞吐、延迟、错误率这些指标 + 缓存对象数据,需要关注自身的cpu和内存使用率
2.2.2 kube-controller-manager
kube-controller-manager 负责监听对象状态,并与期望状态对比,如果状态不一致就进行调谐(reconcile) + 主要关注各个controller的任务数、队列深度 + 与kube-apiserver交互的请求数、耗时、错误数
2.2.3 kube-scheduler
kube-scheduler经过一些打分算法,给pod选取合适的node + 调度框架的各个扩展点、算法的耗时 + 调度队列的任务数、队列深度 + 与kube-apiserver交互的请求数、耗时、错误数
2.2.4 etcd
etcd主要存储各种k8s的对象数据,etcd与kube-apiserver直接交互 + 关注etcd处理的请求量、请求耗时、cache命中情况 + etcd 集群的状态,是否在做snapshot、是否在做数据defrag、leader/leaner以及切换次数 + etcd的db size ,wal写入状态等 + etcd各种操作的耗时、数量情况 + etcd的cpu 内存、fd使用情况
2.2.5 node节点
- node本身的资源(cpu 内存 硬盘 网络 fd等)
- node上容器资源(cpu 内存 硬盘 网络 fd等)
node上组件的监控,kubelet kube-proxy、dockerd、containerd等
2.2.6 工作负载信息
workloads(工作负载)指标,比如业务部署了多少个deployment,部署了多少个pod
资源quota还剩多少
2.2.7 业务监控
业务本身提供的metrics接口,来暴露业务指标
业务进程自身的监控
三 采集方式
3.1 权限
监控对象明确后,就要确定如何收集指标。在收集具体指标前,首先要搞定的就是权限。kubernetes大部分指标的采集都是需要kube-apiserver 授权的。关于kubernetes的authorization,主要包含RBAC、ABAC、Node Authorization、Webhook Authorization。
- RBAC: Role-based access control 是基于角色的访问控制
- ABAC: Atrribute-based access control 是基于属性的访问控制
- Node Authorization: 节点鉴权,专门用户kubelet发出的api请求进行鉴权
- Webhook Authorization: webhook是一种http回调,kube-apiserver配置webhook时, 会设置回调webhook的规则,这些规则中包含了调用的api group、version、operation、scope等信息。
Node Authorization 和 Webhook Authorization是两种专门的鉴权模型。ABAC是用户和权限绑定;RBAC是用户和角色绑定,角色和权限绑定。 ABAC控制粒度更细也更复杂,后续我们主要是RBAC鉴权模式进行采集指标。
3.2 自动发现
搞定鉴权模式后,我们面临的下一个问题是自动发现。对于控制面组件,类似prometheus的static config可以满足需求, 对于使用pod部署的组件,我们都可以利用k8s自 身的特性来动态发现目标,进而采集数据。比如,创建service,然后利用service动态发现对应endpoint的变化,这样pod的ip发生变化也不影响采集。如果 公司已经有其他成熟的服务发现机制,也可以直接利用,比如consul。
3.3 如何部署采集器
搞定了鉴权和自动发现,接下来要考虑采集器以何种方式采集了。
- 控制面组件,首先推荐使用 deployment方式 + 自动发现; 如果控制面组件是二进制方式部署, 可以用deployment+ consul(或者静态抓取方式);
- node节点,首先推荐使用daemonset方式采集node指标和容器基础指标;
- 工作负载,首先推荐使用 deployment方式 + 自动发现;
- 业务监控,首先推荐使用sidecar模式来采集;其次使用集中式的deployment方式采集;
部署yaml文件,我们已经放在k8s目录下: + deployment.yaml 以deployment方式部署 + sidecar.yaml 以sidecar方式部署 + deamonset.yaml 以daemonset方式部署 + in_cluster_scrape.yaml 在pod内抓取指标 + scrape_with_cafile.yaml 用cafile方式抓取指标 + scrape_with_kubeconfig.yaml 用kube-config 文件方式抓取指标 + scrape_with_token.yaml 用token方式抓取指标
四 监控大盘与报警规则
按照梳理的指标,已经将k8s 部分组件的大盘梳理完了,具体可以参考categraf k8s目录下对应的文件。 + apiserver-dash.json + cm-dash.json + sheducler-dash.json + etcd-dash.json + coredns-dash.json
本文先将k8s环境下的监控整体工作做了一个简单介绍,大家先有一个感性认识。后续我们会针对具体的步骤做详细的介绍,欢迎大家点赞、关注和收藏。